
c++之string
模板还没复习,有点不记得了,记得回来填坑。
string是什么
在C++中,string是一个模板类—basic_string的别名,而basic_string是一个封装好的,便于我们对字符序列进行操作的模板类,可以方便的针对单个字符内存占用的问题,实现好几个版本的string,这个模板类提供了很多方便的方法,如size,find…以及操作安全性。定义如下:
Visual Studio:
1 | _EXPORT_STD using string = basic_string<char, char_traits<char>, allocator<char>>; |
G++:
1 | namespace std _GLIBCXX_VISIBILITY(default) |
string工作原理
讲到这个首先要讲一讲char和char*(char[])。
char/char*
在C语言中,没有string类型,只有char类型,所以如果需要表示字符串,需要通过字符数组,也就是char[]或者说是char*。
一个char类型占用一个字节,那么如果一个字符串长度为n,字符数组的长度就是n吗?答案是否定的,原因是内存中需要在尾部有NULL(ASCll码为0)字符作为字符串结尾的判断。
1 | char a[] = "Zierc"; |
上面的代码中,a在内存中的数据如下图:
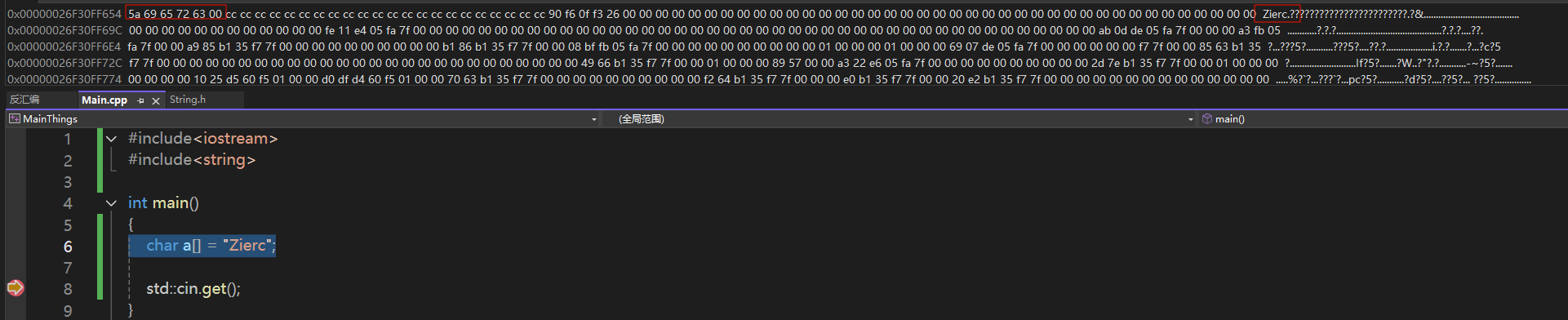
因为"Zierc"在cpp中默认是const char[]类型,所以自动会补上一个0字符。
如果按照数组的初始化方式,不去写这个0,会怎么样呢?
1 | //正确的写法 |
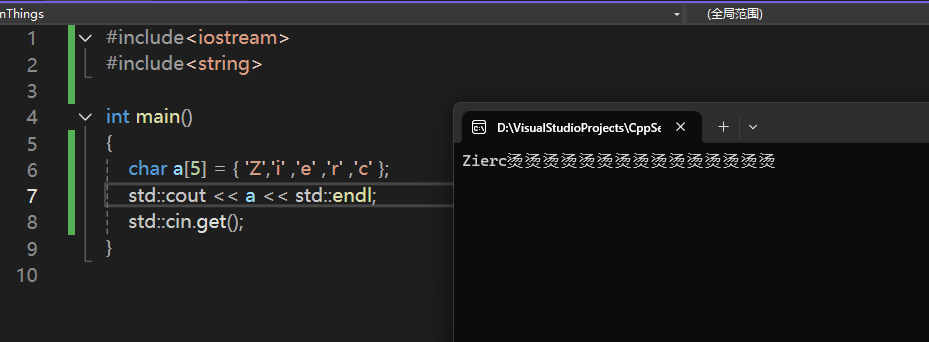
可以看到出现了内存错误访问的问题,还没有报错!这相当危险!
上面介绍的是标准的char,如果需要更多的字符表示,则需要一个字符占用多个字节,可以用到这些类型:
1 | const wchar_t* a = L"两个字节"; |
注意,不同char类型,字符串的初始化方式也不同。
可以发现,wchar_t和char16_t都是两个字节,他们有上面区别呢?区别就是:wchar_t的实际占用取决于编译器,一般来说,在windows中,它占2字节,在linux中,它占用4字节,而char16_t永远是占用2字节。
关于这些孪生兄弟,和编码关系很大,可以先挖个坑,看看后面有无时间研究一下。
string
string本质上就是一个const char[],和原始的字符数组一样,由于需要判断字符串尾部,所以需要多一个字节的空间存放 0来作为结束标志,所以实际长度会是字符串长度+1。
对于string,同样由于编码问题,有几个孪生兄弟:
1 | std::wstring a = L"对应const wchar_t*"; |
string的拼接
在cpp中,所有的字符串常量都会被存储在常量区中(为什么要这样不是很理解,似乎可以实现共享,减少内存占用)
我们随便写一段代码,通过字符串常量初始化一个字符数组,然后获取它生成的汇编文件
cpp:
1 | const char* a = "Zierc"; |
生成的汇编:
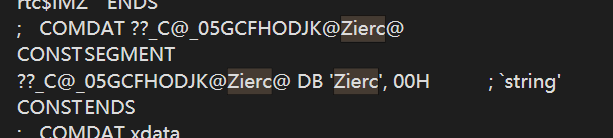
可以看到,确实是在常量区定义了一个字符串
首先,在初始化阶段,由于两个字符串常量指针不能直接拼接,所以不允许出现以下写法:
1 | //Wrong |
如果需要在初始化时进行拼接,可以通过以下两种方法
1 | //1 |
这两种方法本质上是一样的,第二个方法中,字符串尾部的s其实就是一个方法,返回一个初始化为"Zie"的string类型,这样就可以通过string重载的+进行拼接了,也就是第一个方法的做法。
然后是初始化之后的修改,由于这个"Zierc"所在的内存区间是只读的,如果我们想要进行修改,要如何做呢?
实际上,我们拿到是一份常量区数据的复制,而所有修改都是在复制品,也就是一个变量上进行的。
依然是写一段代码,然后看生成的汇编文件,同时也可以通过观察内存变化,来进一步验证。
1 | char a[] = "Zierc"; //line5 |
对应的汇编,只复制了关键部分:
1 | ; COMDAT ??_C@_05GCFHODJK@Zierc@ |
可以看到,当我们初始化一个字符数组时,是将常量复制到变量a$,也就是说实际操作的是这个变量,后面进行修改,也是在这个变量上进行修改。实际上的Zierc一直没动过。
所以这个常量区的Zierc意义是什么呢,我觉得可能一般写cpp都会先定义好全局的const string,这样的话这个常量区的字符串就有意义了。
在内存区中,同样,在修改前后,指针a的地址没有发生变化(图就不附了,偷个懒,感兴趣可以自行验证)。
string段落格式
如果需要输入一整个段落或者是一大串代码,可能就需要使用这种格式:
1 | //1 |
补充
string的定义其实在std的命名空间中,但是string库里面包含了<<符号的重载
小结
本文没有讲太多string的使用,主要是研究工作原理。
就这样,洗澡!
 微信
微信 支付宝
支付宝




